Was ist eigentlich ein Sprachmodell?
02. Dezember 2025
Ein Sprachmodell ist ein System der künstlichen Intelligenz, das darauf trainiert wurde, menschliche Sprache zu verstehen und eigene Texte zu formulieren. Es lernt aus sehr großen Mengen an Textdaten und erkennt dabei Muster, Bedeutungen und typische Sprachstrukturen. Auf dieser Grundlage kann es Fragen beantworten, Inhalte zusammenfassen oder ganz neue Formulierungen erstellen. Man kann sich das so vorstellen, dass das Modell ständig berechnet, welche Wörter als nächstes sinnvoll wären und damit Schritt für Schritt einen Text weiterführt.
Wie funktioniert ein Sprachmodell grundsätzlich?
Die Funktionsweise eines Sprachmodells lässt sich vereinfacht so beschreiben: Beim Training verarbeitet das Modell riesige Textmengen und passt dabei sehr viele interne Parameter an. Dadurch entwickelt es ein Verständnis dafür, wie Sprache aufgebaut ist, welche Wörter häufig zusammen vorkommen und wie Bedeutungen in Texten transportiert werden. Wenn später eine Anfrage gestellt wird, analysiert das Modell den Kontext und erstellt eine passende Antwort, indem es die wahrscheinlichsten Formulierungen auswählt.
Am Ende kann es vorhersagen, welches Wort mit hoher Wahrscheinlichkeit als nächstes in einem Satz folgen sollte. Beispiel: „Die Katze liegt auf dem…“ → „Sofa“ wäre für ein Sprachmodell statistisch ein naheliegendes nächstes Wort.
Technisch basiert diese Fähigkeit häufig auf der sogenannten Transformer-Architektur. Sie ermöglicht es dem Modell, auch längere Textabschnitte zu betrachten und Zusammenhänge über mehrere Sätze hinweg zu erkennen. Deshalb wirken moderne Sprachmodelle deutlich flüssiger und kohärenter als frühere Ansätze, etwa einfache statistische Textsysteme oder klassische Autovervollständigungsfunktionen auf Smartphones. Was genau diese sogenannte Transformer-Architektur ist, erklären dir in einem zukünftigen Blogbeitrag.
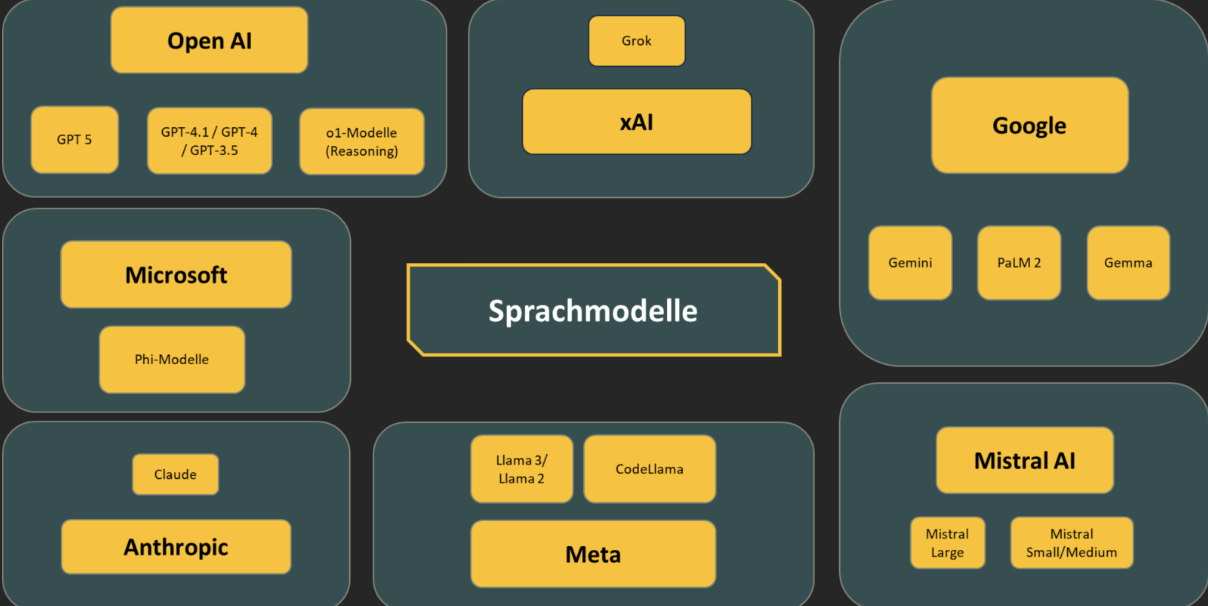
Abbildung 1: Anbieterübersicht von Sprachmodellen
Welche Arten von Sprachmodellen gibt es?
Es gibt eine große Vielfalt an Sprachmodellen, die sich in Größe, Fähigkeiten und Einsatzzweck unterscheiden. Einfache Modelle, wie sie beispielsweise in Smartphones zur Autovervollständigung von Text verwendet werden, arbeiten mit relativ wenigen Parametern und konzentrieren sich auf die nächste sinnvolle Wortvorhersage in kurzen Kontexten. Sie sind schnell und ressourcenschonend, aber inhaltlich begrenzt.
Mittelgroße Modelle werden häufig in Unternehmen oder Fachanwendungen eingesetzt. Sie können nicht nur Sätze ergänzen, sondern auch gezielte Aufgaben bewältigen, zum Beispiel einfache Kundenanfragen beantworten, Produktbeschreibungen verfassen oder interne Dokumente strukturieren. Oft sind sie auf bestimmte Branchen oder Themenbereiche spezialisiert.
Die leistungsfähigsten Modelle sind sogenannte Large Language Models (LLMs), die aus Milliarden Parametern bestehen. Sie ermöglichen komplexe Anwendungen wie Chatbots, die natürliche Gespräche führen, oder Assistenzsysteme, die Forschungstexte zusammenfassen, Code generieren und kreative Ideen entwickeln können. Beispiele für solche Modelle sind GPT-Reihen, PaLM-Modelle oder Llama-Modelle. Einige davon sind kommerziell, andere als Open-Source-Versionen verfügbar, was den Einsatz insbesondere in Forschung und Entwicklung erleichtert.
Die natürliche Sprachverarbeitung (NLP) zielt darauf, dass Maschinen Texte und gesprochene Sprache verstehen, erzeugen und sinnvoll nutzen. Der Weg dorthin beginnt mit Tokenisierung(Wörter/Silben/Teilwörter), geht über Einbettungen (Vektorrepräsentationen mit semantischer Nähe) und mündet in große Sprachmodelle (LLMs), die mithilfe von Transformern lange Zusammenhänge verarbeiten.
Damit gelingen Anwendungen wie Übersetzungen (z. B. DeepL), Frage-Antwort-Systeme und Konversationsassistenten (Siri, Alexa, ChatGPT). Praktische Feinheiten sind hier entscheidend: Feintuning auf fachspezifische Daten macht Modelle treffsicherer; RAG-Ansätze (Retrieval-Augmented Generation) verbinden Modellwissen mit aktuellen Dokumenten. Von Sprache ist der Sprung zu Bildern kürzer, als es scheint – denn unter der Haube arbeiten ähnliche Lernprinzipien.
Zusätzlich gibt es Modelle, die speziell auf bestimmte Aufgaben optimiert wurden, etwa für medizinische Daten, juristische Texte oder wissenschaftliche Literatur. Solche spezialisierten Modelle kombinieren allgemeine Sprachkompetenzen mit fachspezifischem Wissen und eignen sich besonders für professionelle Anwendungen.
Haben wir dein Interesse geweckt? Dann schau doch gerne in unserem Customer Experience Lab in Winterscheid vorbei! Im Customer Experience Lab hast du die Möglichkeit, Sprachmodelle praxisnah kennenzulernen, neue Impulse mitzunehmen und sich zu verschiedenen Chancen und Anwendungsfeldern auszutauschen. Wenn du Interesse an einem Termin hast, nutze dafür gerne unser Kontaktformular. Alle Angebote des Labs sind kostenfrei und stehen für dich offen.
Wenn du wissen möchtest, was künstliche Intelligenz überhaupt ist, schau doch gerne bei unserem vorherigen Blogartikel vorbei.
Jetzt unverbindlich & kostenfrei Termin vereinbaren!
Einfach das untenstehende Formular ausfüllen und den Terminwunsch über das Kommentarfeld äußern
